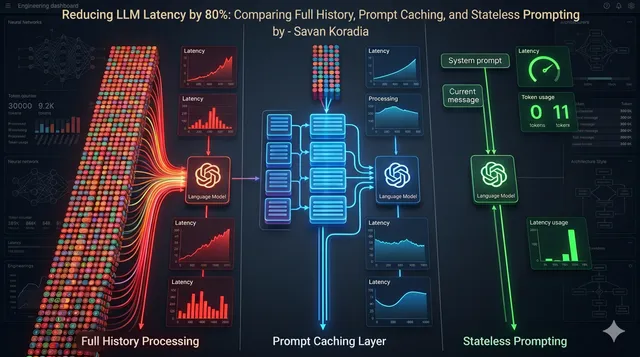
I Reduced My Local LLM Response Time by 83% by Changing One Prompting Strategy
A real-world benchmark comparing full history, prompt caching, and stateless prompting in a local Ollama-powered grammar correction app. Learn how better context management reduced latency by 83% and cut token usage by 62%.