I Reduced My Local LLM Response Time by 83% by Changing One Prompting Strategy
Details a real-world technical benchmark of a local grammar-correction app powered by Ollama. Explains how prompt caching and stateless prompts reduced query latency by 83% and token consumption by 62%.
When developers talk about optimizing LLM applications, the conversation usually revolves around model size, quantization, GPU memory, or inference speed.
However, one of the biggest performance bottlenecks often sits much higher in the stack: how we construct the prompt payload sent to the model.
Every message sent to an LLM includes some combination of:
- System instructions
- Conversation history
- The user’s latest message
The larger that payload becomes, the more work the model must perform before it can generate a response.
For applications that process thousands or millions of requests, inefficient context management can increase both latency and operational costs significantly.
To better understand the impact of context management strategies, I benchmarked three common approaches using a local LLM-powered grammar correction application (Ollama + Gemma3:1b).
The results were surprising.
The Test Scenario
This benchmark was performed using a grammar correction workflow.
A typical request looked like this:
Input
i am going to market yesterday
Output
I went to the market yesterday.
Unlike a conversational assistant, grammar correction is largely a single-turn task. In most cases, previous messages provide little or no value when correcting the current sentence.
This makes grammar correction an ideal workload for evaluating whether conversation history is actually worth sending to the model.
I compared three different context management strategies across an 11-turn session.
Strategy 1: Full History
Every message in the conversation is appended to the prompt.
[
systemPrompt,
...allPreviousMessages,
currentMessage
]This is the default behavior used by many chat applications and LLM clients.
Strategy 2: Full History with Prompt Caching
The entire conversation history is still sent, but the runtime is allowed to reuse previously processed context whenever possible.
[
systemPrompt,
...allPreviousMessages,
currentMessage
]The payload remains identical to Strategy 1, but the runtime can avoid repeating some prompt-processing work.
Strategy 3: Stateless Prompting
Only the system prompt and the current user message are sent.
[
systemPrompt,
currentMessage
]No conversation history is preserved.
Because grammar correction is inherently a single-turn task, this approach is expected to perform well while minimizing context size.
Why Context Size Matters
Before an LLM generates a response, it must process the input context.
As conversation history grows, the amount of text included in each request grows as well.
Without any optimization, larger prompts generally mean:
- More prompt-processing work
- Higher latency
- More tokens consumed
- Increased operating costs when using hosted APIs
Prompt caching can reduce some of this overhead by allowing the runtime to reuse previously processed context.
Stateless prompting takes a different approach: instead of optimizing large prompts, it avoids sending them in the first place.
Benchmark Results
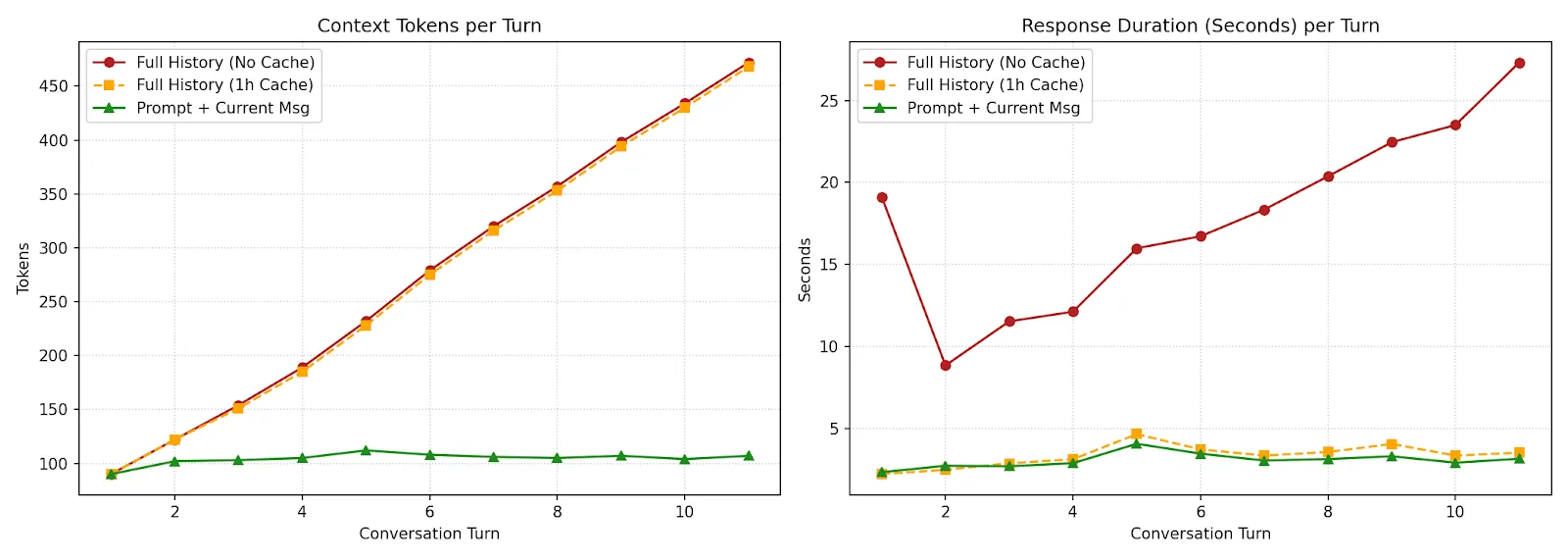
Cumulative Session Latency
The difference between the three strategies became increasingly visible as the session progressed.
| Turn | Full History (No Cache) | Full History (1h Cache) | Stateless (Prompt Only) |
|---|---|---|---|
| Turn 1 | 19.13 seconds | 2.21 seconds | 2.33 seconds |
| Turn 2 | 8.84 seconds | 2.48 seconds | 2.72 seconds |
| Turn 3 | 11.53 seconds | 2.87 seconds | 2.69 seconds |
| Turn 4 | 12.12 seconds | 3.12 seconds | 2.88 seconds |
| Turn 5 | 15.99 seconds | 4.65 seconds | 4.06 seconds |
| Turn 6 | 16.72 seconds | 3.72 seconds | 3.46 seconds |
| Turn 7 | 18.35 seconds | 3.34 seconds | 3.04 seconds |
| Turn 8 | 20.38 seconds | 3.56 seconds | 3.13 seconds |
| Turn 9 | 22.46 seconds | 4.05 seconds | 3.30 seconds |
| Turn 10 | 23.51 seconds | 3.34 seconds | 2.91 seconds |
| Turn 11 | 27.33 seconds | 3.52 seconds | 3.15 seconds |
| Total Session Wait | 🛑 196.36s | ⚡ 36.86s | 🚀 33.67s |
The Full History approach experienced steadily increasing processing times as the conversation grew.
Both caching and stateless prompting dramatically reduced cumulative waiting time.
Compared to Full History, Stateless Prompting reduced total session latency by approximately 83%.
Context Token Usage
Latency tells only part of the story.
The benchmark also revealed substantial differences in context token consumption.
| Strategy | Total Context Tokens | Average Context Tokens per Request |
|---|---|---|
| Full History | ~3047 | ~277 |
| Full History + Cache | ~3012 | ~274 |
| Stateless | ~1149 | ~104 |
Stateless prompting reduced context token usage by roughly 62%.
This reduction occurred because previous messages were no longer included in every request.
Importantly, for this grammar correction workload, removing conversation history did not meaningfully affect the quality of the corrections.
Understanding the Difference
The benchmark highlights two fundamentally different optimization techniques.
Prompt Caching
Prompt caching keeps historical context available for reuse.
Advantages:
- Maintains conversational awareness
- Reduces repeated prompt-processing work
- Ideal for chat assistants and long conversations
Limitations:
- Full context still exists
- Cache effectiveness depends on implementation details
- Context size continues growing
Stateless Prompting
Stateless prompting eliminates historical context entirely.
Advantages:
- Minimal context size
- Predictable token usage
- Consistent latency
- Simplified architecture
Limitations:
- No conversational memory
- Unsuitable for multi-turn reasoning tasks
For workloads where previous messages provide little value, stateless prompting can deliver substantial performance gains with virtually no downside.
When Stateless Architectures Make Sense
Not every AI application needs memory.
Stateless prompting often works well for:
- Grammar correction
- Translation
- Text rewriting
- Classification
- Formatting
- Sentiment analysis
- Content moderation
Conversational history is often more important for:
- General-purpose chat assistants
- Coding copilots
- Research assistants
- Customer support agents
- Long-running AI workflows
The key lesson is simple:
Context should be treated as a tool, not a default.
If your application does not benefit from historical messages, sending them anyway only increases latency and token consumption.
Building Cache-Friendly Systems
For applications that genuinely require history, prompt caching can still provide significant improvements.
To maximize cache effectiveness:
Keep Historical Messages Immutable
Avoid modifying older messages after they have been created.
Bad:
messages.push({
role: "user",
content: userInput,
timestamp: Date.now()
});Dynamic metadata can prevent cache reuse.
Better:
messages.push({
role: "user",
content: userInput
});Keeping historical context stable increases the likelihood of cache hits.
Final Thoughts
This benchmark demonstrates that context management can have a larger impact on application performance than many developers realize.
For a grammar correction workload:
- Stateless prompting reduced total latency by roughly 83%.
- Context token usage dropped by approximately 62%.
- Output quality remained effectively unchanged.
The most important takeaway is not that conversation history is bad.
The takeaway is that different workloads require different context strategies.
Many AI applications inherit chat-style architectures by default, even when their tasks are fundamentally single-turn operations.
By choosing a context strategy that matches the actual problem being solved, developers can significantly reduce latency, lower token consumption, and build more efficient AI systems.
After comparing these strategies, I believe every AI application should display context statistics directly in the chat interface. If users can see CPU usage, memory consumption, and network activity in other software, they should also be able to see how many context tokens are being sent to the model.
A simple panel showing Context Tokens, Response Tokens, Total Conversation Tokens, and a Send Full History checkbox would make context management transparent and help users understand the performance and cost implications of their conversations.